
WordPress Duplicate Content Issues and How to Fix Them
WordPress is a CMS that makes website management easier for online businesses, blogs, and even online shops (WooCommerce). The platform applies most of the best practices automatically, while also having the plugin arsenal for almost everything else.
In regards to SEO, WordPress is pretty much awesome out of the box. However, the ease of publishing duplicate content can become an issue with WordPress if you do not pay close attention to it, which can really mess up any SEO efforts put into your site.
Google wants to reward rich, unique, relevant, informative and remarkable content in its organic listings – and it has raised the quality bar over the last few years.
In this article, we are going to explain what exactly is duplicate content, how it happens, and how to deal with it.
Table of Contents:
What is Duplicate Content?
Duplicate content is such content that completely matches or is remarkably similar to other content on the web. This type of content is often found on different URLs, and sometimes even different domains. Most of the duplicate content happens involuntarily, sometimes being the result of technical implementations.
Why is Duplicate Content Bad for SEO?
Because of the multiple sources of duplicate content, search engines experience trouble when deciding which URL deserves a higher spot in their results. That’s why the search engines often put all URLs with specific duplicate content at lower ranks, preferring other pages for their better spots in the search results.
With WordPress websites, content duplication is often a reason for the site not to rank. The traditional meaning of duplicate content is “such a piece of content that is the exact match of another (from wording to code).” With WordPress, duplicate content can be a bit different from that definition, but the issue still needs to be addressed.
Unmanaged duplicate content can cause three main problems for search engines:
- They are unaware of which version of the same content to include or exclude when ranking a URL;
- It’s hard to decide between directing link metrics to one page, or spread it between multiple pages;
- Search engines are not entirely sure which version to rank for query results.
As for site owners, they suffer in terms of rankings and traffic losses. The losses are caused mainly from the following issues:
- Search engines also have a job, and it is to provide the best search experience for users around the globe. Duplicate content is an issue that they try to resolve by picking only one version of the same content. As a result, all other copies of that content will be “hidden.” If your site turns out to be one of those copies, people won’t be able to see and visit your site while browsing via a search engine.
- The link equity can be further lessened because other sites also have to choose between duplicates. So, instead of all inbound links to point to the same piece of content, they are linking to various pieces, spreading this link fairness among duplicates. Inbound links are a factor in SEO ranking, which is why all of this could impact the specific content’s search visibility.
- The value of the article can also be lessened because of duplicate content. When your article is available on two or more URLs, the link juice would spread between all versions of the article.
- The crawl budget could be wasted. Crawl budget is the number of pages that crawlers like Googlebot index on any website within a given timeframe. If a website has too many internal duplicate pages, the chances for Googlebot to crawl those pages instead of the important ones gets higher.
Does Google Have a Duplicate Content Penalty?
There are lots of myths surrounding duplicate content and whether it’s penalized by Google or not. Yes, we said myths, because a penalty is not exactly what duplicate content gets. As we already mentioned, this type of content is inconvenient for search engines because it makes their job harder. In that sense, it doesn’t get actually penalized, but rather gets the “silent treatment,” if you will. And yes, for content creators, that is the equivalent of a penalty.
However, people actually keep thinking they get a penalty from search engines because their content is not ranking. It’s a common misconception that duplicate content pages compete against each other because of the lack of knowledge they have on the matter.
Here are some of Google’s thoughts on duplicate content:
- Your site will not be penalized because of duplicate content. It just might not be lucky enough to be listed.
- Google knows that users are looking for diversity in their search results, and thus the search engine needs to consolidate and show only one version of the same content.
- Google actually has algorithms designed to prevent duplicate content from affecting webmasters. The algorithms work to group different versions of your content into a cluster. The most ‘correct’ URL in that cluster is displayed, consolidating various links from pages within the said cluster to the URL being shown in the search engine’s results.
- Google believes that just the existence of duplicate content is not grounds for action, except when it’s created on purpose to manipulate search results.
- The worst thing that can happen when managing duplicate content is for a little less desirable version of the same content to be shown in the search results.
- Google always tries to determine the original source, but we need to understand that with all the content available on the Internet, this job is not easy at all.
- Googlers advise not to block access to duplicate content. If they are not able to crawl all the versions of duplicated content, they won’t be able to consolidate all the signals.
So, the conclusion here is—there is no actual duplicate content penalty by search engines, but it still harms your SEO in a major way.
The Panda Update
Back in February 2011, Google released a search filter, known as the Panda Update. This update was made in order to stop sites with poor quality content from using certain “tricks” to make their way to the high rankings.
The Panda algorithm update addressed more than a few problems when it comes to the Google Search Engine Result Pages (SERPs). Those are:
- Duplicate content;
- Thin content – weak pages with large amounts of irrelevant content and resources.
- Low-quality content – pages that lack in-depth information and provide little to no value to their visitors and readers.
- Lack of authority or trustworthiness – content produced by sources that are not considered verified.
- Content-farming – large numbers of pages that are low-quality, often generated from other sites.
- Low-quality user-generated content (UGC) – an example here can be a blog that publishes short guest posts, which are full of grammatical and spelling errors, in addition to lacking proper information on a certain matter.
- High ad-to-content ratio – pages full of paid ads, lacking original content.
- Low-quality content that surrounds affiliate links (paid affiliate programs).
- Websites blocked by users – sites that a number of human users are either blocking in the search engine results (either directly or by using a browser extension to do that).
- Content mismatching search query – pages that are saying they provide quality content, when in fact they don’t, which leads to disappointment in visitors (false advertising, aka clickbait).
Causes for WordPress Duplicate Content
The reasons for duplicate content are plenty. In fact, there are dozens of them. Most of those reasons, as Google believes, are technical. One of the most usual cases is when someone decides to put the same content in two or more different places, without clearing out which one is the original. Perhaps the main problem is that developers are not used to thinking as users or browsers. So, here are some of the main causes of duplicate content in WordPress and overall.
Tags
Using tags in WordPress often results in duplicate content. When you tag a post or a page, WordPress creates a separate page for that particular tag, gathering snippets (or even full articles) from all pages and posts that include the tag. If this tag is the same as a category on your WordPress site, then you would create a competitor page on your own website.
Often tags are modified versions of themselves, which also creates similar content that competes with itself. If that happens, none of those pages will rank, which is definitely not good for SEO.
Categories
Category pages usually include lots of posts – similar to tags. They have H1 tags which are the same as in your articles. However, Category pages will not always answer a question or provide the perfect solution, mainly because they are post snippets, therefore not suitable when someone is looking for answers. That’s what makes them usually considered thin content.
URL Parameters for Tracking and Sorting
Another cause of duplicate content issues is using URL parameters, such as click tracking and some analytics code. Let’s take, for example,
http://www.example.com/post-x/
http://www.example.com/post-x/?source=rss
In the eyes of a search engine, those are two different URLs. The second one will help you with statistics about where your visitors come from, but it may also prevent your site from ranking as well as you wish.
This goes for all parameters that are added to a URL, without changing the primary piece of content inside said URL. No matter the purpose, such URLs count as duplicate content.
Scrapers and Content Syndication
Most of the time duplicate content is just inside the borders of your website. It is not an uncommon case for generally alternative websites to take (“scrape”) your website content without your agreement on the assumption that increasing the volume of pages on their site is a good long-term strategy despite the relevance or uniqueness of that content. By doing this, the foreign website does not provide valuable information for search engines, and they may not get that a piece of content originates from your website, therefore deciding this content is duplicate.
As your website grows in popularity, more and more scrapers will start using its content.
Session ID Duplication
As a website owner, and most commonly when managing an online store (WooCommerce), you would probably want to keep track of your visitors and let them keep track of their shopping cart, even if they leave it and come back later. For that to happen, you need to provide users with a Session, which is a form of history of the actions they took while they were on your website. There is a unique identifier called Session ID, which is to be stored somewhere with the purpose of keeping your visitors’ sessions. Nowadays, the most common practice to do that is by implementing cookies.
Keep in mind that search engines usually don’t store cookies and thus some systems go back to using Session IDs in the URL. With that, there are URLs generated for every Session ID, which is unique for that specific session and results in duplicate content.
Parameters Order
Here’s one more common cause for duplicate content — order of parameters. You should know that CMSs usually don’t use clean URLs, meaning they tend to add stuff into a URL (numbers of ids, categories, etc.). For example, a URL that has /?id=13&cat=21 will give you the same result as a URL with /?cat=21&id=13. The issue here is that the search engine sees those two URLs as different, therefore rendering the content inside duplicate.
Comment Pagination
In WordPress, as well as in some other systems, there is an option for paginating comments. This is not a recommended practice, because if you paginate your comments, it leads to duplicated content (/comment-page-1, /comment-page-2, etc.).
Filters and Sorting
Filtered (or faceted) navigation is used mainly by e-commerce websites. It’s the type of navigation where users can sort items on the page. Faceted navigation works by adding parameters to the URL’s end.
With Ecommerce, there are usually lots of combinations with certain filters (sizes, colors, etc.), and thus using faceted navigation often results in a lot of duplicate (or near-duplicate) content.
See the following URLs as an example:
www.yourstore.com/shoes.html?fresh=size=46
www.yourstore.com/shoes.html?size=46&fresh
You can see that while the URL’s are unique, their content is almost identical. What’s more, the parameter order often does not even matter.
WWW vs. non-WWW Consistency
When both versions of your website (WWW and non-WWW) are accessible, search engines might consider that duplicate content.
HTTP/HTTPS Duplication
Similar to WWW vs non-WWW, if you have HTTP and HTTPs versions of a website, there are still chances for the same issue to occur.
Forward Slash at the End of URLs
Not everyone knows that Google actually treats URLs with or without trailing slashes as unique. That makes example.com/post/ and example.com/post unique in the eyes of the search engine. So, in case your content is available at both URLs, that can lead to duplicate content issues.
You can easily check by inputting both versions of a page on your site. The best result would be if only one version to load and the other to redirect.
Print-Friendly URLs
Website admins often create printer-friendly versions of page content. They do this for convenience – to help users print the content that’s available on their website. Print-friendly versions of a page or a post have the same content as the original. The only difference is in the URL – example.com/post vs. example.com/print/post. Put simply, those print-friendly URLs are PDF versions of a piece of content from the site. They count as duplicate content because Google can read PDF files. The content on print-friendly URLs is not only accessible via different URLs, but it has also actually been copy-pasted (on 2 or more pages).
How to Identify Duplicate Content
You can identify duplicate content using a lot of methods, both manually and with the help of specific tools.
Use a Duplicate Content Checker
When it comes to finding duplicate content, there are plenty of tools available. It’s a matter of personal choice which one you will pick to use, but it’s probably best to use more than one tool since there are often differences in what duplicate content tools offer.
CopyScape
CopyScape is pretty straightforward – all that needs to be done is insert a link in the box on the homepage. After you do that, CopyScape returns a number of results. However, be aware that without a premium account, you will get only the top 10 results.
Each of the results is clickable for more details about it. If the results are below 10% of one of your posts or pages – it’s okay. However, in case someone copies more than 20% of your content, you can consider sending them an email, politely explaining that what they are doing is not professional, asking them to change the copied text.
Siteliner
For an internal duplicate content check, you can use Siteliner. It will help you find duplicate content on your own website.
The Siteliner duplicate content check provides a lot of information, but the free version is limited to 250 pages once per 30 days. After doing a search, you will be able to see your internal duplicate content percentage. Seeing a high percentage, in this case, is not a reason to panic, because Siteliner also shows excerpts duplicate content.
SeoReviewTools
The best thing about SeoReviewTools is that it’s free to use. What’s more, you have more than 30 tools that will help you while working on your website. The duplicate content checker is one of them, and all you have to do to perform one is to confirm you are not a robot via entering a captcha. The tool will show you both internal and external duplicate content.
Keep in mind that SeoReviewTools is not as powerful as some of the premium duplicate content tools, but it’s still helpful in most cases.
Serpstat
Serpstat is a powerful premium all-in-one SEO platform. With it, you can also see a list of pages with identical titles or description tags. Go to the Serpstat Meta tags section, which is inside the Audit module.
Some alternatives to Serpstat are:
- HubSpot (Freemium);
- Moz (Premium);
- SEO Powersuite (Freemium);
- SEMrush (Freemium);
- Ahrefs (Premium).
Manual Duplicate Content Check
Using Google is one of the easiest ways to find out whether you have an issue with duplicate content on your WordPress site. There are various search operators which are quite helpful in such cases.
For example, if you want to find all URLs that have a specific keyword in inside their content, you need to type the following line in the Google search bar:
site:example.com intitle:"WordPress"
Where example.com is the site your site and WordPress is, well, the keyword you need to examine.
After you hit enter, Google will display all of the site’s pages that contain your chosen keyword. If you make the “intitle” part more specific (e.g., “WordPress is the best”), the fewer results you will get. With that in mind, you can even search for whole sentences, especially if something tells you that you have already written a piece of content in the exact same way, but you can’t put your finger on it.
Sometimes when performing this type of search, Google might display a message at the very end of your results (last page, at the bottom):
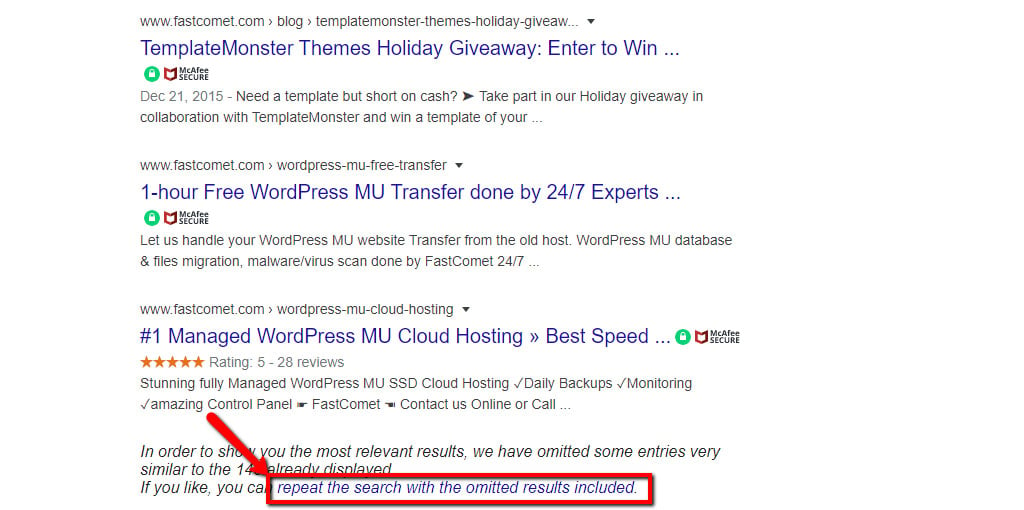
This is proof that Google is not displaying every single possible result, and that there is indeed duplicate content being scraped. Feel free to try it yourself and click on the link to see those additional results. We also recommend fixing as many of them as possible.
How to Fix Common Duplicate Content Issues
Use Rel=Canonical
Sometimes you might not be able to dispose of a duplicate piece of content (mainly with articles), even if you know it’s not the correct URL. To solve this issue, search engines have introduced the element called Canonical link, which you need to place in the <head> section of your site. It looks like this:
<link rel="canonical" href="http://example.com/wordpress/seo-plugin/" />
In the ‘href’ section of the canonical link, you have to place the correct canonical URL for your article. Whenever a search engine that supports canonical finds that link, it will perform a soft 301 redirect and transfer most of the link juice to your actual canonical page.
Keep in mind that this process is a bit slower. Do it after you have no more options for the regular 301 redirect.
Use 301 Redirecting
Sadly, there are those cases where you simply cannot prevent your system from creating improper URLs for pieces of content. In such cases, you can redirect them. So, after you resolve as much duplicate content as you can, just redirect the rest to the proper canonical URLs.
How to Avoid Duplicate Content
Once you know which one is your canonical URL, you will have to start with the canonicalization. Basically, you need to start helping search engines find the canonical version of a page and do it as quickly as possible. There are four methods of solving (or preventing) the duplicate content issue:
- By not creating duplicate content in the first place;
- By redirecting duplicate content to the specific canonical URL;
- By adding a canonical link element to the duplicate page;
- By adding an HTML link from the duplicate to the canonical URL;
We have already given some cases for duplicate content in WordPress. Here are the fixes for them:
- Session IDs. Those can often be disabled in the system settings;
- URL Parameters for Tracking and Sorting. Canonicalize all parameterized URLs to SEO-friendly versions without tracking parameters.
- Scrapers and Content Syndication. In this case, the first thing you do is run a whois check on the site that is scraping your content. Then you have a few options:
- Contact the website owner and ask them to remove the site or the duplicated content;
- Contact the domain registrar or the hosting company that serves the scraping website;
- Ask Google to deindex pages with the stolen content under the Digital Millennium Copyright Act.
- Tags. Either stop using tags altogether or add a meta robots noindex dofollow. That will tell Google and other search engines that the page is thin, but to continue following, crawling, and indexing your website. This way, Google will be aware that those tag pages are not as important, and you have also provided information where your good content is.
- Categories. If you have a website where categories are dedicated to channels and niches within them, then users may find those categories useful. That’s why you treat categories a bit differently than you would do tags. With categories, you need to add a meta robot index and dofollow tags, while also creating unique titles and copy for the category. Additionally, if schema is relevant, include it as well.
- Trailing slashes vs. Non-trailing-slashes. Use a 301 redirect of the undesirable version (a matter of personal choice) to the one you want to use. Also, be consistent with your internal linking. Choose either with or without trailing slashes and stick with your choice for all URLs on your site.
- WordPress comment pagination. Disable the feature from your WordPress dashboard → Settings → Discussion:
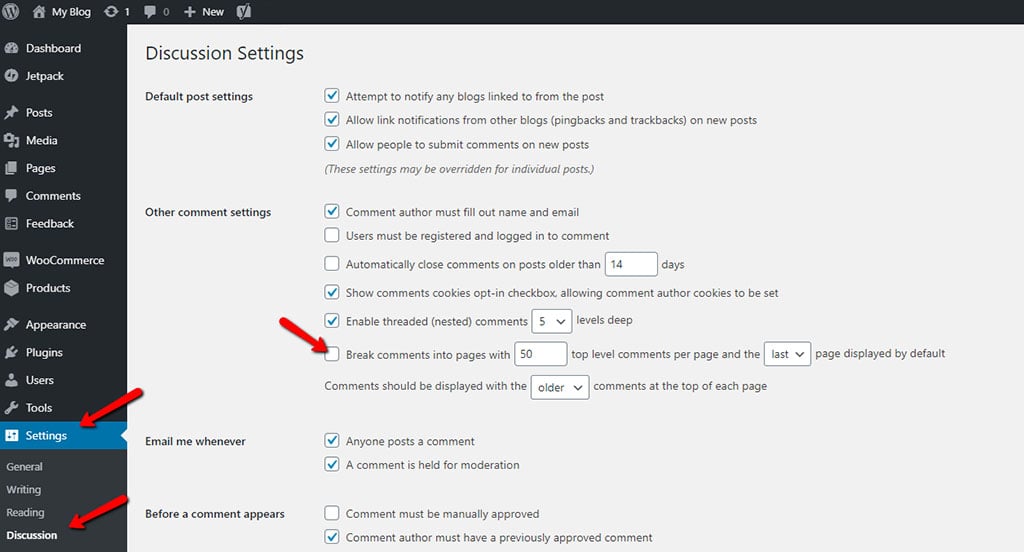
- Parameters in a different order. Ask your programmer to put parameters always in the same order (aka URL factory).
- WWW vs. non-WWW and HTTP vs HTTPS. pick one and stick with it. You can do this by just performing a 301 redirect for the one to the other (no matter which one you choose). You can set a preference in Google Search Console. However, you will have to claim both versions of the domain name.
- Print-friendly URLs. Canonicalize the print-friendly version to the original.
Your goal should be preventing duplicate content from appearing because it’s by far the best solution to the problem. After you are more familiar with the matter, you will be able to avoid duplicate content much easier by implementing the proper type of research.
You Should Fix Duplicate Content, for the Sake of SEO
Duplicate content is everywhere on the web. It’s extremely hard to find a WordPress site with lots of pages and complete absence of duplicate content. If you make sure to keep an eye for duplicate content and manage it correctly, all should be fine.
One has to keep in mind that there are certain things, such as scraping or spam, that can cause problems. However, for the most part, issues are caused by improper settings. For some additional info on the matter of duplicate content, you can always check out Google’s help section.
Myths about Google penalizing duplicate content need to be gone for good. For that to happen, the truth has to be shared and false information—to be corrected. If not, there will always be people who believe duplicate content is seen as a penalty.
If you had any doubts yourself, we are confident that now you got the picture. There are more than enough ways to deal with duplicate content, and even if you don’t do it yourself, Google will do their best to solve the problem for you.

The latest tips and news from the industry straight to your inbox!
Join 30,000+ subscribers for exclusive access to our monthly newsletter with insider cloud, hosting and WordPress tips!
Joseph is part of the FastComet Marketing team. With years of content writing experience behind him, it's one of his favorite activities. Joseph takes part in the SEO of the FastComet website and blog. His goal is to write comprehensive posts and guides, always aiming to help our clients with essential information. Joseph also has a thirst for knowledge and improvement, which makes the hosting environment a perfect place for him.



Comments (4)
Hey everyone!
How do you handle duplicate content on your WordPress site? I’ve been noticing some issues with my SEO and think this might be the culprit. Any tips or tricks that have worked well for you?
Hello!
You are correct that duplicate content can have a significant impact on SEO. The tips and tricks that worked best for us are what we have outlined in the blog post above. Please try our suggestions out, as they should help you identify the duplicate content on your website.
Duplicate content is a huge issue on any website. Sometimes this is quite puzzling www, non www, HTTP vs https, canonical and so many things.
Oh, Indeed. Duplicate content is the most pervasive and underestimated SEO issue. There are so many duplication forms that you have to watch out for, and one small technical error can lead to literally thousands of duplicate pages. However, being able to fix the issues that lead to duplicate content alone can result in a 20% or higher increase in organic traffic. Imagine if you have millions of visitors, that can be hundreds of thousands in additional revenue.